Mục lục
Observability: Giám sát hệ thống phần mềm
Năm 2020, một công ty Fintech ở Hà Nội triển khai feature rút tiền nhanh và tự tin live vào ngày thứ Sáu 17h. Ngày thứ Bảy lúc 8h sáng hôm sau, app bắt đầu slow. Họ có metrics, logs, traces… nhưng mất 45 phút mới locate được: một microservice ghi 500GB logs vào disk trong 15 phút, full disk, timeout tất cả request liên quan. Nguyên nhân? Developer lên production mà quên cập nhật lại mức log.level.
Đó là lúc họ mới nhận ra: có monitoring không bằng có observability.
Monitoring ≠ Observability
Monitoring là kiểm tra xem hệ thống có "sống" hay không – CPU, memory, response time đo được sẵn. Observability là khả năng hiểu được tại sao hệ thống hành xử như vậy mà không cần biết trước nó sẽ hỏng cái gì.
Kiểu monitoring cũ: bạn định nghĩa 50 dashboards, 200 alerts, mỗi alert kích hoạt có ghi chú "nếu xảy ra thì check file X, xem log Y". Kiểu observability: bạn tha hồ khám phá dữ liệu, hỏi câu hỏi bất kỳ lúc nào và có đáp án.
Khác nhau lắm. Monitoring chính là bạn là sherlock ngồi nhà, observability là bạn có cả một phòng lab đầy đủ.
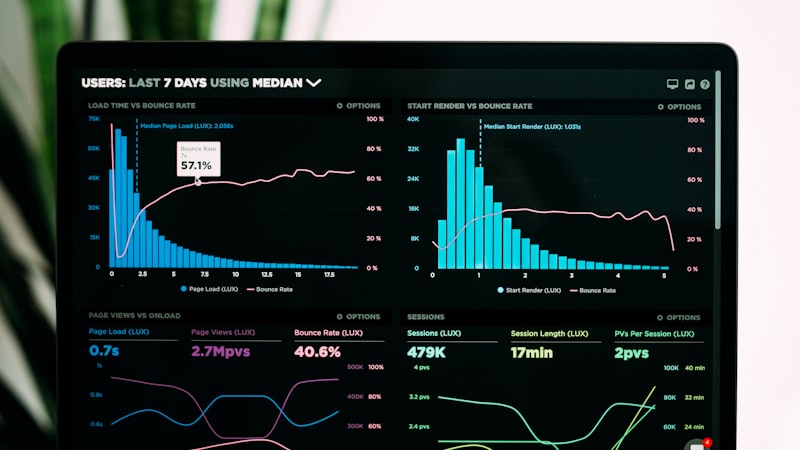
Cột trụ ba: Metrics, Logs, Traces
Metrics cho bạn cái nhìn rộng. Prometheus + Grafana là combo quốc dân ở Việt Nam – giá rẻ, đỡ đơn độc lập, support tốt. Nhưng nhớ rằng: metric là aggregate, nó không nói câu chuyện từng request.
Logs là storytelling, từng chi tiết. Có cái hay của logs là nó free – ứng dụng của bạn cứ ghi ra, nhưng bao giờ bạn cần phải có log aggregation (Elasticsearch, Loki, hoặc S3 chuỗi) để query lại. Cảnh báo: đừng log bừa, ai đó phải đọc chúng. Anh em ở BigTech vẫn bị "log explosion" – 1TB logs/ngày mà khi cần tìm tí gì cũng mất vài phút.
Traces là bạn theo dõi request từ lúc vào cho tới lúc ra, đi qua 12 microservice, vào database, cache, message queue. Tools: Jaeger, Zipkin, hay dùng Datadog (có tiền thì Datadog ngon lắm, không có tiền thì tự deploy Jaeger).
Chia sẻ bài viết

